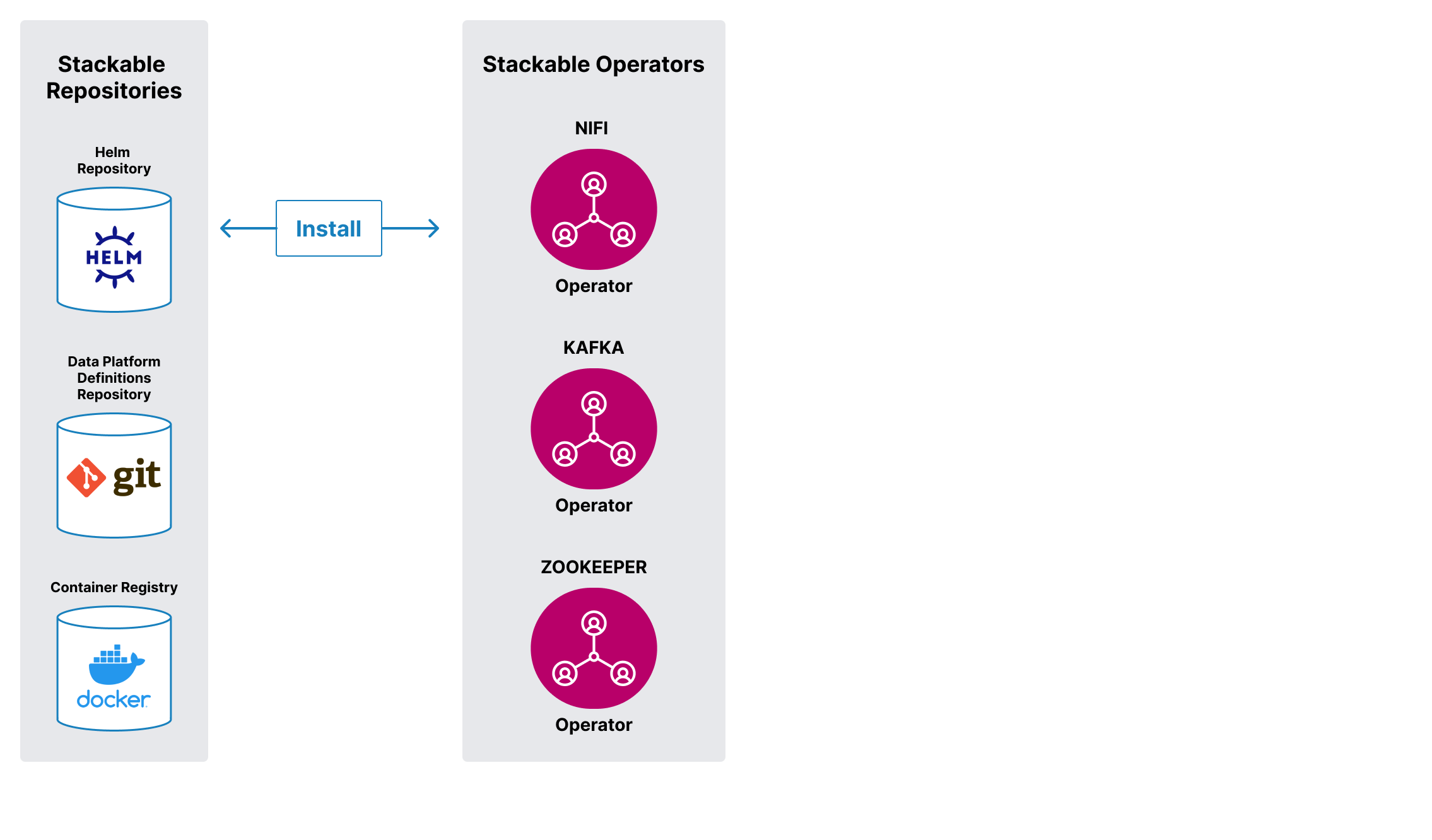
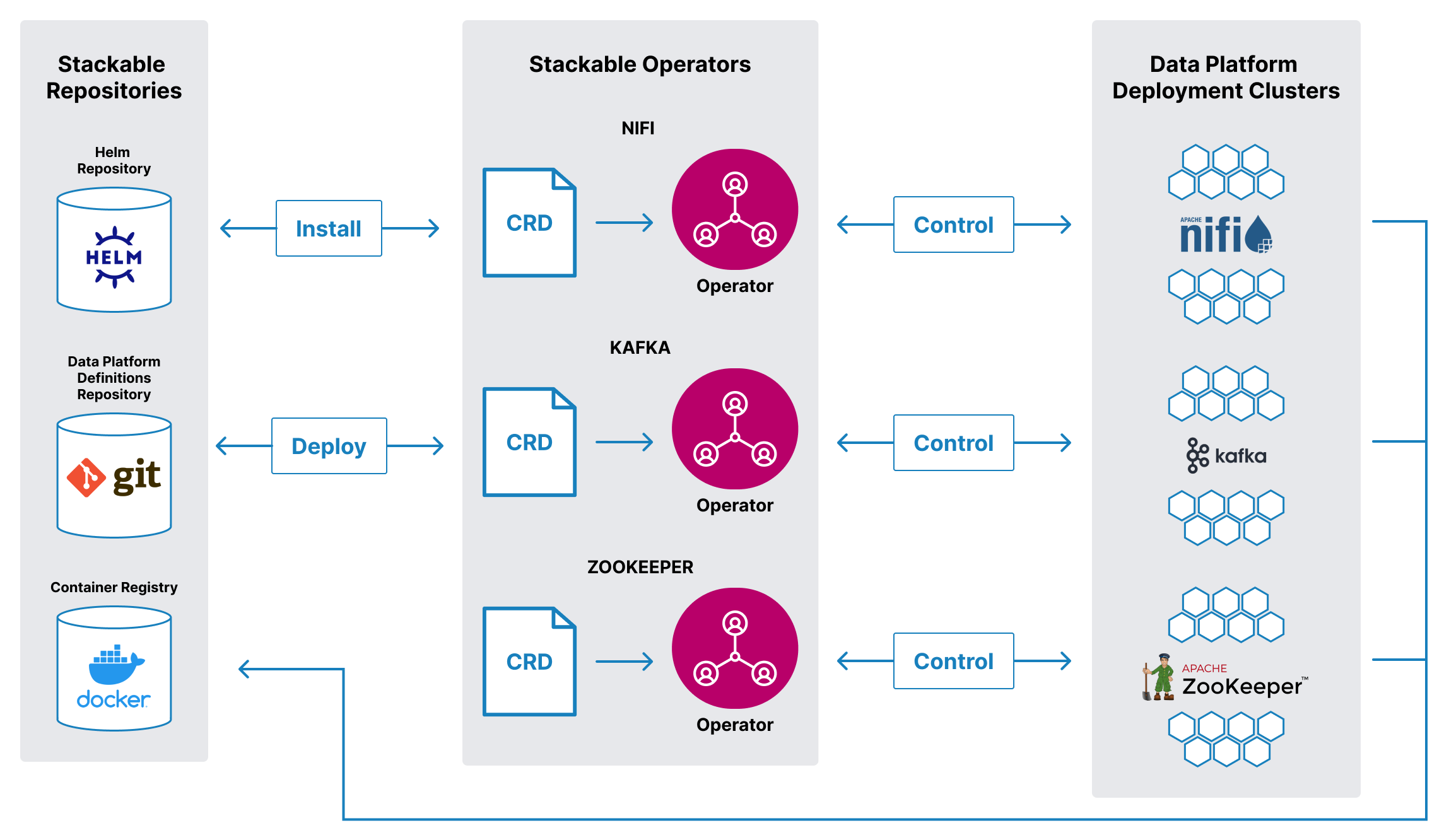
Stackable bietet Dir eine abgestimmte Auswahl der besten Open-Source Data-Apps wie Kafka, Druid, Trino oder Spark. Speichere, verarbeite und visualisiere Deine Daten mit den neuesten Versionen. Bleibe auf der Höhe der Zeit, nicht hinter ihr.
Alle Data-Apps arbeiten nahtlos zusammen und können im Handumdrehen hinzugefügt oder entfernt werden. Basierend auf Kubernetes läuft es in allen Umgebungen – on prem oder in der Cloud.
Erstelle einzigartige und unternehmensweite Datenarchitekturen. Die Plattform unterstützt z.B. moderne Data Warehouses, Data Lakes, Event Streaming, Machine Learning oder Data Meshes.