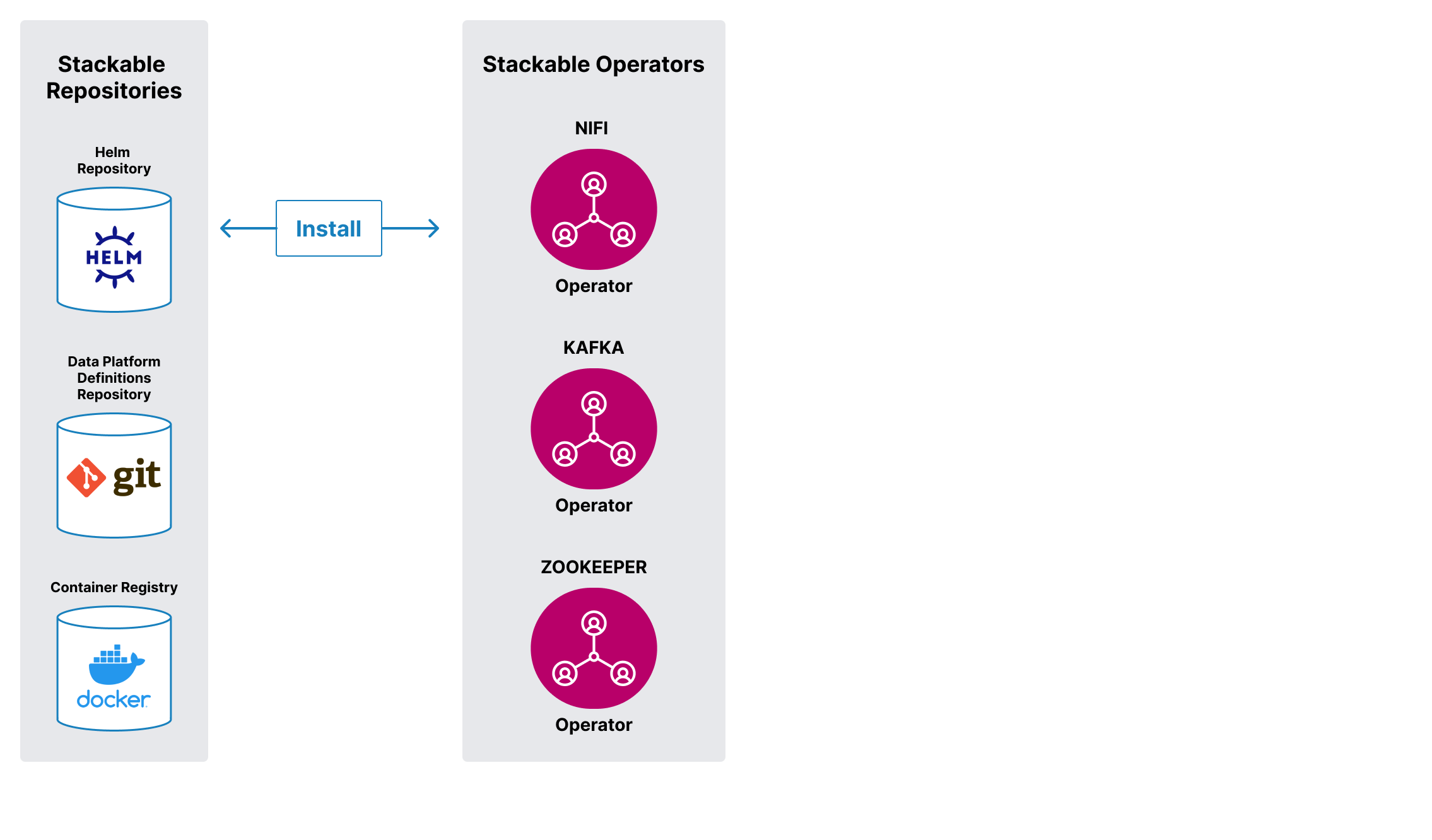
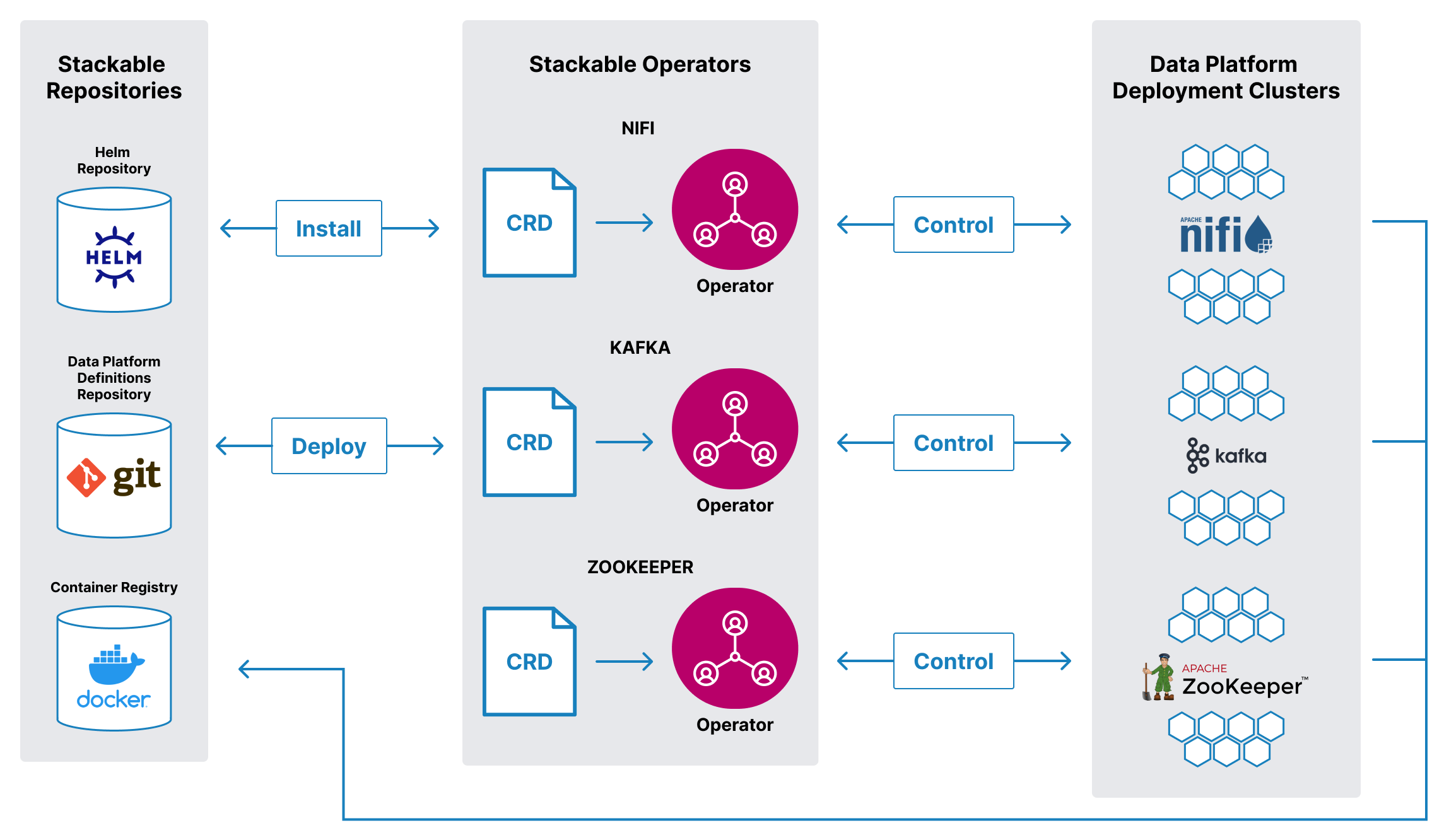
Stackable gives you a curated selection of the best open source data apps like Kafka, Druid, Trino or Spark. Store, process and visualize your data with the latest versions. Stay with the curve, not behind it.
All apps seamingly work together and can be added or removed in no time. Based on Kubernetes, it runs everywhere – on prem or in the cloud.
Use it to create unique and enterprise-level data architectures. It supports e.g. modern Data Warehouses, Data Lakes, Event Streaming, Machine Learning or Data Meshes.